 Léo — Agent emails
Léo — Agent emails Mia — Agent avis
Mia — Agent avis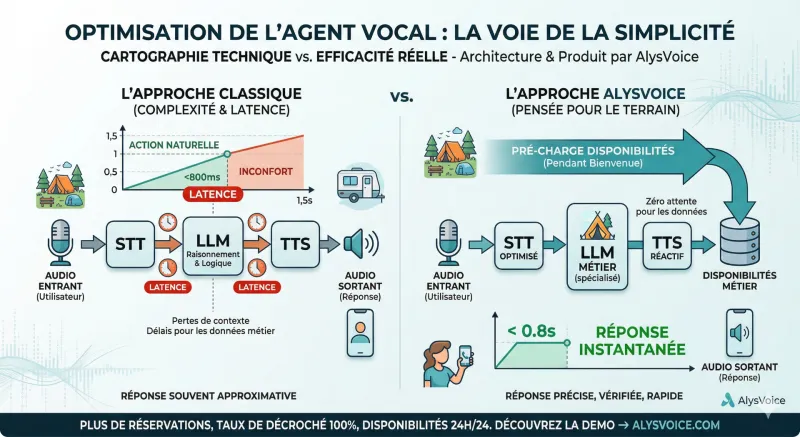
Quand on parle d'agent vocal IA — ou de callbot — aujourd'hui, on entend souvent des raccourcis. "C'est juste un répondeur amélioré." Ou à l'inverse : "C'est de la magie." La réalité est plus nuancée, et surtout plus technique. Voici une cartographie honnête des quatre générations de traitement vocal automatisé — avec leurs compromis réels en termes de latence, de coût, et d'expérience utilisateur.
Génération 1 — Le répondeur classique (IVR/DTMF)
Le répondeur à touches, ou IVR (Interactive Voice Response), est la technologie qui a équipé les centres d'appels pendant trente ans. Le principe est d'une simplicité brutale : un arbre décisionnel préenregistré, des messages audio figés, une navigation au clavier (Tapez 1 pour...).
Sur le plan technique, c'est du déterminisme pur. Aucun traitement du signal vocal au sens propre : le système ne "comprend" pas la voix, il détecte uniquement des tonalités DTMF (Dual-Tone Multi-Frequency) ou, dans les variantes plus récentes, des mots-clés isolés via reconnaissance phonémique basique.
La latence est quasi-nulle côté traitement — les fichiers audio sont préchargés en mémoire, la réponse est immédiate. Mais la latence perçue par l'utilisateur est catastrophique : naviguer dans un arbre de cinq niveaux pour obtenir une information prend 90 secondes là où une conversation naturelle en prendrait dix.
Le vrai problème : le répondeur classique est conçu pour dérouter le client, pas pour le servir. Il réduit la charge opérationnelle au prix de l'expérience.
Génération 2 — TTS : quand la machine apprend à parler
Le Text-to-Speech (synthèse vocale) marque la première vraie rupture. On passe des messages préenregistrés à une voix générée dynamiquement à partir de texte. L'information peut être fraîche, personnalisée, variable.
Architecturalement, un système TTS repose sur un pipeline en plusieurs étapes : normalisation du texte (expansion des abréviations, des nombres), analyse linguistique (prosodie, phonèmes), puis synthèse acoustique. Les approches modernes utilisent des modèles neuronaux (WaveNet, Tacotron, VITS) qui génèrent des formes d'onde directement, produisant une qualité vocale remarquablement naturelle.
La latence est ici un enjeu central. On distingue deux métriques critiques :
- TTFB (Time To First Byte) : temps avant que le premier octet audio soit disponible. Les meilleurs modèles cloud sont aujourd'hui entre 200ms et 600ms.
- Latence de streaming : la capacité à commencer à jouer l'audio avant que la synthèse complète soit terminée. Le streaming par chunks de 50-100ms est désormais la norme pour les cas d'usage temps réel.
Le TTS seul ne résout pas le problème de compréhension : le système parle, mais n'écoute toujours pas vraiment.
Génération 3 — ASR/STT : quand la machine apprend à écouter
Le Speech-to-Text (reconnaissance automatique de la parole, ASR) est la brique symétrique du TTS. Elle transforme le signal audio en texte, ouvrant la voie à une compréhension réelle de l'intention utilisateur.
Sur le plan technique, les architectures modernes d'ASR reposent majoritairement sur des transformers (Whisper d'OpenAI, Nova de Deepgram, Conformer de Google). Ces modèles sont entraînés sur des milliers d'heures de parole et gèrent nativement les accents, le bruit de fond, les hésitations.
Les paramètres clés à calibrer pour un usage en téléphonie sont :
- VAD (Voice Activity Detection) : détecter quand l'utilisateur s'arrête de parler. Trop agressif, le système coupe la parole. Trop laxiste, la latence explose.
- End-of-utterance detection : le délai de silence toléré avant de considérer qu'une phrase est terminée. En pratique, entre 500ms et 1200ms selon les contextes.
- Domaine spécifique : les modèles généralistes peinent sur le vocabulaire métier. Booster des mots-clés spécifiques (emplacement, mobil-home, acompte) via des paramètres de pondération améliore significativement la précision.
La combinaison TTS + STT permet de construire un dialogue. Mais il manque encore une pièce : la compréhension sémantique et la capacité à raisonner.
Génération 3.5 — Le pipeline LLM orchestré (STT → LLM → TTS)
C'est l'architecture dominante aujourd'hui dans les agents vocaux IA de qualité production. Le pipeline est le suivant :
Audio entrant → STT → Texte → LLM → Texte → TTS → Audio sortant
Ce que le LLM apporte : la compréhension de l'intention, la gestion du contexte conversationnel, la capacité à appeler des outils externes (function calling), et la génération de réponses adaptées. On passe d'un arbre décisionnel à un raisonnement.
La latence est le défi central de cette architecture. Chaque étape introduit de la latence :
| Étape | Latence typique (bon cas) |
|---|---|
| STT (streaming) | 100–300ms |
| LLM (first token) | 300–800ms |
| TTS (TTFB) | 200–500ms |
| Total perçu | 600ms–1,6s |
En dessous de 800ms de latence totale perçue, l'interaction commence à se sentir naturelle. Au-delà de 1,5s, la conversation devient inconfortable — les silences sont trop longs, le cerveau humain les interprète comme des bugs ou de l'incompréhension.
Les leviers d'optimisation sont nombreux : streaming à chaque étape du pipeline, mise en cache agressive des données métier pour éviter les appels API pendant la conversation, choix de modèles plus légers mais plus rapides pour la génération, déploiement géographique proche des fournisseurs de téléphonie.
Génération 4 — S2S : la promesse du Speech-to-Speech natif
Le Speech-to-Speech natif représente la prochaine frontière. Des modèles comme GPT-4o en mode audio, ou Gemini Live, traitent directement le signal audio en entrée et génèrent directement de l'audio en sortie, sans passer par une étape de transcription texte intermédiaire.
L'avantage théorique est considérable : éliminer les latences de conversion, mais surtout préserver les informations paralinguistiques — le ton, l'hésitation, l'émotion, le rythme — qui se perdent dans la transcription texte. Un modèle S2S peut théoriquement détecter qu'un client est agacé à sa façon de parler, pas seulement aux mots qu'il choisit.
En pratique, les limites restent réelles en 2025-2026 :
- Contrôle limité : il est difficile de contraindre précisément le comportement d'un modèle S2S. Les gardes-fous et la personnalisation fine sont plus complexes à implémenter qu'avec un pipeline LLM texte classique.
- Intégration d'outils : le function calling — appeler une API tierce pendant la conversation — est moins mature dans les architectures S2S qu'en mode texte.
- Coût et disponibilité : les modèles S2S sont significativement plus coûteux à inférer et moins disponibles en production à grande échelle.
- Prévisibilité : pour des contextes métier critiques (réservations, données clients, informations contractuelles), la prévisibilité et le contrôle du pipeline texte restent un avantage déterminant.
Le S2S est une technologie à surveiller de très près. Elle n'est pas encore, à date, le bon choix pour des déploiements B2B exigeants qui nécessitent fiabilité, personnalisation fine et intégration profonde avec des systèmes métier.
Le cas AlysVoice — Une architecture pensée pour le terrain, pas pour les benchmarks
Chez AlysVoice, on a fait un choix délibéré : ne pas utiliser le S2S natif pour notre agent vocal destiné aux campings. Ce choix n'est pas un retard technologique — c'est une décision d'ingénierie.
Notre contexte est précis : un client appelle un camping pour savoir si un mobil-home est disponible le 15 juillet. Il a peut-être appelé trois fois sans réponse ce mois-ci. Il a des questions sur les tarifs, les animations, les conditions d'annulation. Chaque seconde de silence est une friction. Chaque réponse approximative est une perte de confiance.
Ce qu'on a construit à la place, c'est un pipeline qui élimine la latence là où ça compte vraiment : les données métier. La latence d'un LLM, on l'accepte et on l'optimise. Mais la latence d'une requête à un système de gestion de campings pendant une conversation vocale, c'est inacceptable.
Le résultat : une conversation qui se sent naturelle non pas parce qu'on a un modèle audio-natif, mais parce qu'on a éliminé les points de friction réels. Eva ne fait jamais attendre un client pour consulter des disponibilités. Elle connaît les règles spécifiques de chaque camping. Elle sait quand transférer vers un humain. Elle parle avec une voix française chaleureuse, pas robotique.
Un répondeur classique dit : "Nos bureaux sont fermés, rappelez demain." Un agent S2S générique dit quelque chose de naturel, mais ne sait pas si le camping a encore de la place pour 4 personnes du 15 au 22 juillet. Eva répond, vérifie, informe — et le fait en moins de deux secondes.
C'est ça, la vraie mesure d'un agent vocal utile.

Eva est l'agent vocal IA de la plateforme AlysVoice, spécialisé camping. Standard téléphonique 24h/24, connecté à votre PMS, multilingue. Taux de décroché 100%.